
Zählschleifen zum Zeit vertrödeln
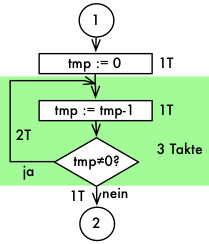 Eine Möglichkeit Zeitverzögerungen zu erreichen ist den Prozessor mit Zählen zu beschäftigen:
Eine Möglichkeit Zeitverzögerungen zu erreichen ist den Prozessor mit Zählen zu beschäftigen:
Der Systemtakt sei 1 MHz, ein Taktzyklus benötigt 1 us. |
 |
- tmp wird nicht 0 (grün), benötigt 3 Takte pro Umlauf
- tmp wird 0, benötigt 2 Takte zu Punkt 2, wenn die Initalisierung ldi tmp,0 mit einem Takt dabei hinzugerechnet wird, werden dann wieder 3 Takte gezählt (der letzte Lauf).
- Angenommen tmp wird statt mit 0 mit 1 initalisiert, werden 3 Takte zwischen 1 und 2 benötigt.
- Bei 8 Bit ist 0-1 = 255; 0 entspricht 256
Lösung, betrachte die Werte von tmp vor brne loop:
Von 255 bis 1 wird nach loop gesprungen: 255*3 Takte. Im Fall tmp = 0 wird die Schleife beendet: 2 Takte; den Takt der Initialisierung dazu sind es dann 3 Takte.
Summe: 256*3 = 768 Takte = 768 µs zwischen 1 und 2
Länger warten mit nop
ldi temp,0 ;mit 0 initialisieren
loop:
dec temp ;temp um 1 erniedrigen
nop ;tue 1 Takt nichts
brne loop ;solange != 0 springen
weiter...Es gibt einen Befehl nop "No Operation" der nix tut ausser 1 Takt Zeit kosten und 1 Adresse (2 Byte) Programm-Speicher verbrauchen:
Der nop-Befehl benötigt einen Takt und verlängert die Durchlaufzeit.
Die Summe der Zeit ist nun 256*4 = 1024 somit warten wir 1024 µs = 1,024 ms.
Länger warten mit zwei Schleifen
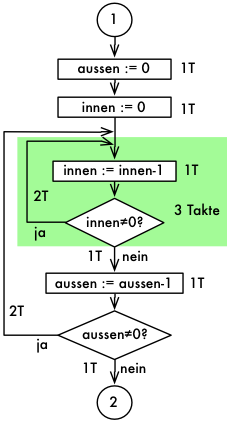 Durch Verschachteln von zwei Schleifen kann erheblich länger gewartet werden, der Systemtakt betrage 1MHz, die Taktzeit ist 1us. Wir ermitteln die maximal mögliche Wartezeit:
Durch Verschachteln von zwei Schleifen kann erheblich länger gewartet werden, der Systemtakt betrage 1MHz, die Taktzeit ist 1us. Wir ermitteln die maximal mögliche Wartezeit:
ldi aussen,0 ;Register auf 0 initialisieren
ldi innen,0 ;Register auf 0 initialisieren
loop:
dec innen ;innen um 1 erniedrigen
brne loop ;solange ungleich 0 springen
dec aussen ;aussen um 1 erniedrigen
brne loop ;solange ungleich 0 springen
weiter...Ermitteln der Takte (Blockdenken)
Die innere Schleife benötigt 255 * 3 + 2 (letzter Lauf) Takte = 767 Takte, betrachte dies als langes nop.
Die äussere Schleife braucht 255*(767+1+2) für den Rundlauf und 767+1+1 für den letzten Durchgang = 256*(767+3)-1 = 197119 Takte.
Fehlen noch die 2 Takte für die ldi am Anfang: 2 + 197119 = 197121Takte ca. 0,2 s
Alternative Rechnung (Flussdenken)
Bei der alternativen Rechnung wird gezählt, wie oft ein Befehl im Programmablauf ausgeführt wird: Programmflussdenken.
Die innere Schleife benötigt 256 + 510 + 1 = 767 Zyklen und wird 256 mal durchlaufen macht 196352 Zyklen.
Dazu kommen noch Initialisierung und dec aussen 256 mal und brne loop somit ergibt sich: 2 + 196352 + 256 + 510 + 1 = 197121 Zyklen also ca. 0,2 s warten.
Leichter verständlich ist der Ansatz sich Blöcke vor zu stellen.
Genau 1 ms warten
wait1ms:
ldi tmp,250 ;initialisieren
loop:
dec tmp
nop
brne loop
weiter..Bei 1 MHz genau 1 ms warten geht mit einer Schleife und nop: 1000 / (1+1+2) = 250
Analyse: 1 (ldi tmp) + 249 * 4 (Schleifendurchläufe) + 3 (letzter Durchgang) = 1000 Takte.
Alternative Rechnung: 1 (ldi) + 250 *(1 (dec) + 1 (nop)) + 249 * 2 (brne Sprung) + 1 (brne kein Sprung)= 1000 Takte!
Dieses Code-Beispiel lässt sich also mühelos einstellen von 1 * 4 µs bis 256 * 4 µs.
Beachte: Bei einem 8 Bit-Register gilt: 256 = 0 (0-1 -> 255)
Überprüfen der Zeiten durch Messung mit Frequenzzähler oder Speicheroszilloskop
init: ;initalisieren nach Reset
ldi tmp, low(RAMEND) ;Stackp. init
out SPL,tmp
sbi DDRB,PB0 ;PB0 als Ausgang
main_loop:
; Warteschleife z.B. rcall wait10ms
sbi PINB,PB0 ;PB0 := !PB0 (2 Takte)
rjmp main_loop ; 2 TakteDas Beispiel bezieht sich auf einen ATtiny2313 mit 1 MHz Systemtakt und PB0 wird als Ausgang für das Messgerät verwendet. Um genaue Messungen erhalten zu können sollte statt des internen RC-Oszillators ein Quarz-Oszillator zum Einsatz kommen. Das Messgerät wird auf die Messung der Periodendauer eingestellt. Eine Periode ist die Zeit bis sich ein Signalverlauf wiederholt, hier z..B. zwischen zwei positiven Taktflanken.
Bei der 1 ms Warteschleife sollte 2008 µs angezeigt werden: Nach jedem Durchgang wird der Pegel umgeschaltet, die Zeit ist: 2 * (Warteschleifenzeit + 2T (sbi) + 2T (rjmp)).
Genau 10 ms warten als Unterprogramm
wait10ms: ; rcall 3 Takte
ldi aussen,10
loop_aussen:
ldi innen,250 ;initialisieren
loop_innen:
dec innen
nop
brne loop_innen
dec aussen
brne loop_aussen
ret ;zurueckspringen 4 TakteDie 1 ms Verzögerung einfach 10 mal ausführen lassen?
Flussrechnung: 3 (rcall) + 1 (ldi aussen) + 10*1000 + 10 (dec aussen) + 9*2 (brne ausgeführt) + 1 (brne nicht ausgeführt) + 4 (ret) = 10037 µs
Die 37 us zu viel können eingespart werden: Die innere Schleife nicht mit 250 laden, sondern mit 249. Die Zeit verkürzt sich um 10*4 Takte. Jetzt fehlen 3 Takte, mit 3 nops am Ende ausgleichen!
Überprüfen Sie die Lösung mit einem Messgerät.
Erstellen Sie eine Lösung, die ohne nop in der inneren Schleife auskommt und messen Sie die Zeit.
wait10ms:
ldi aussen,10
loop_aussen:
ldi innen,249 ;initialisieren
loop_innen:
dec innen
nop
brne loop_innen
dec aussen
brne loop_aussen
nop
nop
nop
retUnterprogramm ca. 100 ms warten
wait100ms:
ldi aussen,130
loop_aussen:
ldi innen,0 ;Register auf 0
loop_innen:
dec innen
brne loop_innen
dec aussen
brne loop_aussen
ret ; RücksprungEs muss nicht immer so genau sein – etwa 100 ms bei 1 Mhz Takt warten:
Die innere Schleife benötigt 1+255*(1+2)+1+1 = 256 * 3 = 768 Zyklen = 0,768 ms Mit der äusseren Schleife ergibt sich 3 (rcall) + 1 (ldi) + 130 * 768 + 130 * 1 (dec) + 129 * 2 (brne) + 1 (brne) + 4 (ret) =
4 + 130 * 769 + 129 *2 + 5 = 100237 Zyklen = 100,237 ms.
Erstellen Sie einen PAP für das Unterprogramm.
Lösung
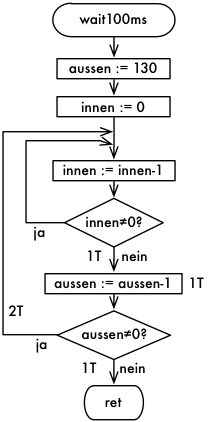
Entwickeln Sie eine Lösung, die genau 100 ms wartet.
Nix genaues mehr mit Interrupts
Sobald man Timer und Interrupts verwendet kann es mit der Genauigkeit vorbei sein. Der Ablauf wird unterbrochen und zur Interrupt-Routine verzweigt..
Aufgaben
Der µC sei mit 4 MHz getaktet, erstellen Sie eine Lösung für eine 1 ms Warteschleife und messen Sie die Genauigkeit.
Der µC sei mit 6 MHz getaktet, erstellen Sie Quellcode für eine 5 ms Warteschleife und messen Sie die Genauigkeit.
Doppelblinker
Ein ATtiny 2313 wird mit 4MHz betrieben an PB0 soll zunächst ein 1kHz-Signal ohne Verwendung von Interrupts ausgegeben werden.
- Erstellen Sie den Asseblercode und einen PAP.
- Implementieren und testen Sie ihre Lösung, verwenden Sie ein Oszilloskop und Frequenzzähler um die Genauigkeit zu überprüfen
Als Erweiterung soll nun an PB1 ein 1Hz Signal ausgegeben werden, dass mit einem Timerinterrupt erzeugt wird.
- Erweitern Sie den Assemblercode entsprechend.
- Wie wird das 1kHz Signal durch die Erweiterung beeinflusst?
- Implementieren und testen Sie ihre Lösung, verwenden Sie ein Oszilloskop und Frequenzzähler um ihre Erwartungen zu überprüfen.
Nachschlag: Lange warten mit nur einer Schleife
Lutz Lißeck schrieb mir eine sehr interessante Mail:
..ich bin auf Ihrer Webseite über die Warteschleifenprogrammierung beim AVR gestolpert. Hier wird eine Verzögerung nach klassischem Beispiel realisiert, in dem in verschachtelten Schleifen Rechenzeit verbraten wird. Die Verschachtelung der Schleifen macht aber die Berechnung von Wartezeiten (unnötig) kompliziert.
Der AVR kann auch mit Zahlen größer als ein Byte rechnen, dazu wurdem dem Controller spezielle Flags spendiert (dazu gibt es auch ein gutes App-Note von Atmel). Wird damit einen Zähler mit 16, 24, 32 oder mehr Bits programmiert, so läßt sich die Verzögerungszeit viel einfacher berechnen. Wie das gemacht wird, hatte ich vor einiger Zeit bereits in einem Forum auf Mikrocontroller.net gepostet [mikrocontroller.net/forum/read-4-11426.html#1142].
Auf den Mailtext folgend ist diese Routine bereits als Makro verpackt, das lnop-Makro muss allerdings evtl. direkt in das Verzögerungsmakro geschrieben werden (alternativ kann auch 2x nop verwendet werden), da AVRASM Makros in Makros (noch?) nicht unterstützt.
;***************************************************************************
;* lnop
;***************************************************************************
;* Typ : Macro, Öffentlich ;* Kurzbeschreibung : Quasi ein NOP-Befehl, der aber 2 Zyklen benötigt
;* Eingabe : keine
;* Ausgabe : keine
;* Benutzte Register : keine
;* Zyklen : 2
;* PrgMem-Verbrauch : 1 Words
;***************************************************************************
; Langer NOP
; Braucht 2 Zyklen zur Verarbeitung, aber nur ein Word Code.
.macro lnop
; rjmp $ + 1 ; Für AvrTerse (Muss im listfile zu c000 kompiliert werden)
rjmp PC + 1 ; Für AVRASM (Muss im listfile zu c000 kompiliert werden)
.endmacro
;***************************************************************************
;* delay_flex3Kern
;***************************************************************************
;* Typ : Makro, Öffentlich
;* Kurzbeschreibung : FlexiWait mit 3 freiwählbaren Registern,
;* die mit der Verzögerungszeit initialisiert sein
;* müssen. Verzögerungsbereich: 10 - 167,7M Zyklen
;* Eingabe : @0: Lowbyte, @1: Midbyte, @2: Highbyte
;* @0-@2: Alles initialisierte Register ab R16
;* Zugelassener 24-Bit-Wertebereich:
;* $1 - $ffffff ($0 entspr. $1000000) ;* Ausgabe : keine
;* Benutzte Register : Status, @0-@2
;* Zyklen : 24-Bit-Wert * 10
;***************************************************************************
; Flexible Waitroutine zum abwarten von bel. Zyklenanzahlen
; Eingabe: 24-Bit in drei Registern aufgeteilt.
; Verzögerung: (24-Bit-Wert * 10) = Zyklen
; Variablen: @0 Low-Byte, @1 Mid-Byte, @2 High-Byte ; (alles Reg. oder Reg.Def's von R16-R31)
; Beispiel:
; ; Register mit Verzögerung initialisieren
;
; .set delayzyklen = 1000000
;
; ldi r16, low(delayzyklen) ; 1
; ldi r17, byte2(delayzyklen) ; 1
; ldi r18, byte3(delayzyklen) ; 1
;
; delay_flex3Kern r16, r17, 18
;
; Gesammtverzögerung bis hier: 3 + 10*delayzyklen
.macro delay_flex3Kern
; Schleifenkern:
; Großen Zähler decrementieren
delay_f3K_W1: subi @0, 1 ; 1
sbci @1, 0 ; 1
sbci @2, 0 ; 1
lnop ; 2 (LNOP)
nop ; 1
lnop ; 2 (LNOP)
brne delay_f3K_W1 ; 2 (1)
nop
.endmacro